I think code quality is always important, but it's less important for terminal code which implements a specific set of features using robust APIs underneath. Low code quality becomes a much bigger issue when the code is supposed to deliver well-defined abstractions on which other code can rely.
If you are a serious software developer, then you will probably be able to explain both what your code does (i.e. what spec it implements) and how it does it (what does it call, what algorithms does it use, what properties does it rely on?). With the advent of LLMs, people have started to accept not having a clue about the "how", and I fear that we are also starting to sacrifice the "what". Unless our LLMs get context windows that are large enough to hold the source of the full software stack, including LLM-generated dependencies, then I think that sacrificing the "what" is going to lead to disaster. APIs will be designed and modified with only the use cases that fit in the modifying agents context window in mind with little regard for downstream consequences and stability of behavior, because there is not even a definition of what the behavior is supposed to be.
Unit testing is much much harder when you have functions spanning thousands of lines and no abstractions. You have to white box test everything to ensure that you hit all code paths, and it is much more expensive to maintain such tests, both as a human and LLM. I don't think this can be ignored just because LLMs are writing the code.
I think more people should focus on using LLMs to relieve cognitive load rather than parallelize and overload their brains. We need to learn to live with the fact that humans are not good at multi-tasking, and LLMs are not going to make us better at it.
I have started using Claude to develop an implementation plan, but instead of making Claude implement it and then have me spend time figuring out what it did, I simply tell it to walk me through implementing it by hand. This means that I actually understand every step of the development process and get to intervene and make different choices at the point of time where it matters. As opposed to the default mode which spits out hundreds of lines of code changes which overloads my brain, this mode of working actually feels like offloading the cognitive burden of keeping track of the implementation plan and letting me focus on both the details and the big picture without losing track of either one. For truly mechanical sub-tasks I can still save time by asking Claude to do them for me.
I've been using a POC-driven workflow for my agentic coding.
What I do is to use the LLM to ask a lot of questions to help me better understand to problem. After I have a good understanding I jump into the code and code by hand the core of the solution. With this core work finished(keep in mind that at this point the code doesn't even need to compile) I fire up my LLM and say something like "I need to do X, uncommited in this repo we have a POC for how we want to do it. Create and implement a plan on what we need to do to finish this feature."
I think this is a good model because I'm using the LLM for the thing it is good at: "reading through code and explaining what it does" and "doing the grunt work". While I do the hard part of actually selecting the right way of solving a problem.
This resonates with me because I've been looking for a way to detect when I would make a different decision than the LLM. These divergence points generally happen because I'm thinking about future changes as I code, and the LLM just needs to pick something to make progress.
Prompts like "list your assumptions and do not write any code yet" help during planning. I've been experimenting with "list the decisions you've made during implementation that were not established upfront in the plan" after it makes a change, before I review it, because when eyeballing the diff alone, I often miss subtle decisions.
Thanks for sharing the suggestion to slow it down and walk the forking path with the LLM :)
Some of us love it, bit intense sometimes, but fun. So I guess we get to decide it ourselves what we prefer.
I know many will then say, BUT QUALITY, but if you learn to deal with your own and claude quirks, you also learn how to validate & verify more efficiently. And experience helps here.
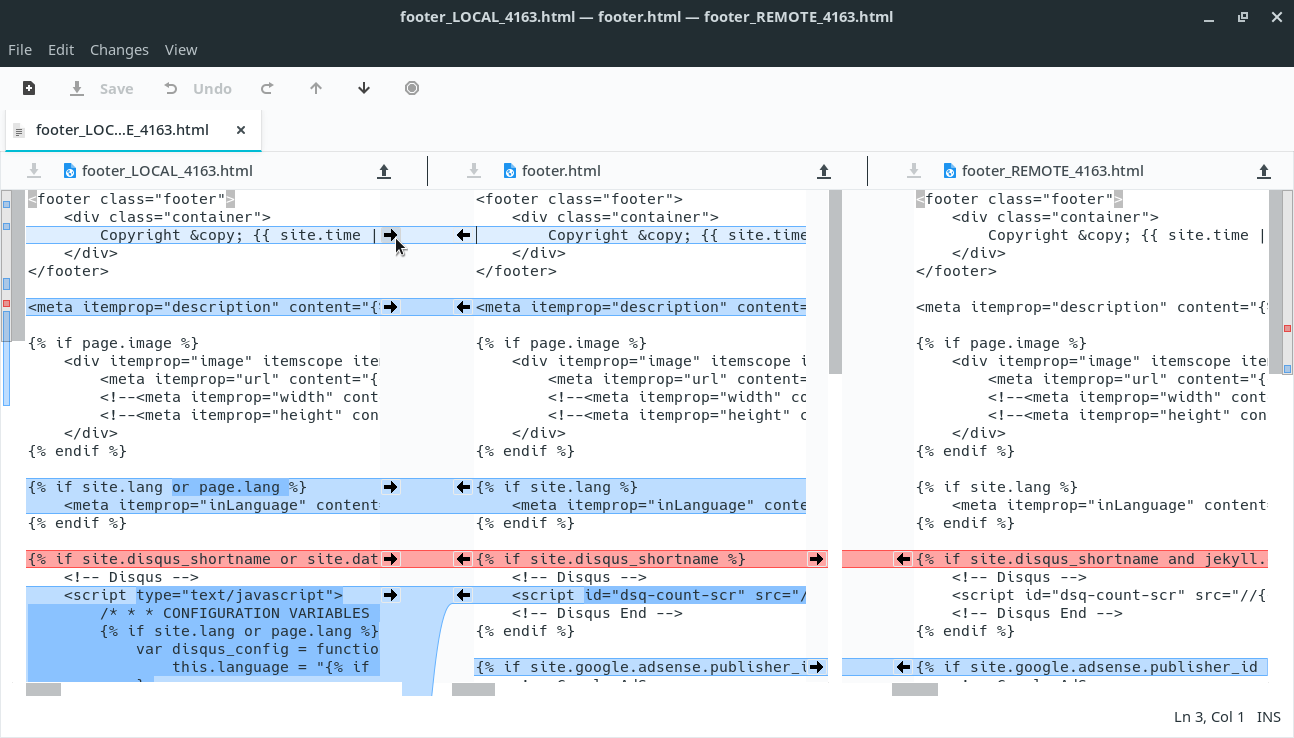
The thing about how merges are presented seems orthogonal to how to represent history. I also hate the default in git, but that is why I just use p4merge as a merge tool and get a proper 4-pane merge tool (left, right, common base, merged result) which shows everything needed to figure out why there is a conflict and how to resolve it. I don't understand why you need to switch out the VCS to fix that issue.
<<<<<<< left
||||||| base
def calculate(x):
a = x * 2
b = a + 1
return b
=======
def calculate(x):
a = x * 2
logger.debug(f"a={a}")
b = a + 1
return b
>>>>>>> right
With this configuration, a developer reading the raw conflict markers could infer the same information provided by Manyana’s conflict markers: that the right side added the logging line.
That still have an issue with the vocabulary. Things like "theirs/our" is still out of touch but it's already better than a loose spatial analogy on some representation of the DAG.
Something like base, that is "common base", looks far more apt to my mind. In the same vein, endogenous/exogenous would be far more precise, or at least aligned with the concern at stake. Maybe "local/alien" might be a less pompous vocabulary to convey the same idea.
I'll be honest, as a fairly skilled and experienced programmer who isn't a git expert, I know what HEAD means, but when I'm rebasing I really have no idea. It all seems to work out in the end because my collaborative work is simple and usually 2–3 people only, so I'm never rebasing against a ton of commits I lack context for (because 90% of them are my commits since I'm usually dealing with PRs to my open source projects rather than someone else's).
HEAD is "the thing we're editing now" but that's not terribly useful when rebasing since you're repeatedly editing a fake history.
Git leaks a lot of implementation details into its UX. Rebasing is meant to be equivalent to checking out the "base" branch and cherry picking commits onto it. Therefore "ours" during a rebase is the base branch.
The meaning of "ours" and "theirs" is always the same, but the "base" of the operation is reversed compared to what you might be used to during merge.
Rebasing can be confusing and hard and messy, but once I learned that rule and took the time to internalize it, I at least never got confused on this particular detail again.
> fake history
That's the thing, it's not actually fake history. Git really is doing the things it looks like it's doing during a rebase. That's why you can do all kinds of weird tricks like stopping in the middle to reset back a commit in order to make a new intervening commit. The reason you can abort at any time with (almost) no risk is because the old history is still hanging around in the database and won't be removed until GC runs, usually long after the rebase is settled.
Learning git properly is pretty much "read Git book at least 3 times".
All of it makes sense and is decently intuitive once you know how internals work.
People keep imagining git as a series of diffs while in reality it's series of the filesystem tree snapshots + a bunch of tools to manage that and reconcile changes in face of merge. And most of that can be replaced if the builtins are not up to task. And the experience is getting slowly better but it's balance between power users and newbies, and also trying to not break stuff when going forward.
Now of course that sucks if programming is not someone's day job but there is plenty of tools that present simpler workflows built on top of that.
Also git store (almost?) all its operations in the reflog. They have identifier like commits so you can reset to them and restore the original state of the working directory (mostly after an automatic rebase gone wrong).
That's the thing, they're not "like commits", they are the actual original commits. It's a history of where the HEAD ref used to be. Eventually those commits will be pruned out of the tree if/when the reflog expires because there is nothing left pointing to them. But otherwise they are normal commits.
It's interesting that once even C programmers, like Linus, become really experienced, they embrace the wisdom that functional programmers are forced to swallow anyway.
> HEAD is "the thing we're editing now" but that's not terribly useful when rebasing since you're repeatedly editing a fake history.
You got two things wrong here. Firstly, HEAD isn't 'the thing you're editing now'. HEAD is what you have already committed. If you want to edit the HEAD, you have to either amend the commit or reset and redo the commit. (To make the situation even more complex, the amended or overridden commit remains in the repo unchanged, but orphaned.)
The actual thing being edited is a 'patch' that will eventually be converted into a new commit (snapshot). If you're doing a rebase and want to see the next patch in the pipeline that you're editing now, try this:
git rebase --show-current-patch
Secondly, rebase is not editing a fake history. Rebase is creating a new (and real) history by repeatedly cherry picking commits from the old history based on the rebase plan. HEAD is the tip commit of the new history under construction. On completion of the rebase, the branch ref of the old history is switched to the new history, where HEAD is now at. Meanwhile, the old history remains in the repo unchanged, but again orphaned.
All the orphaned commits are still visible in the HEAD's reflog. You can use it to undo the rebase if you wish.
I agree that the entire thing is confusing as hell. But I have a bunch of aliases and scripts that show you the process graphically in realtime. You can use that awareness to make the right call every time. I'm thinking about converting it into a TUI application and publishing it.
Seriously! I have too many years of software development experience, but I use Visual Studio UX to handle pretty much all git operations. And always merge.
I have better things to do in my life than "internalizing" anything that doesn't matter in the grand scheme of things.
I don’t like that approach, because people who work like that commit all kind of crap to repo or cry that GIT ate their homework…
Then we have line ending conflicts, file format conflict UTF8-BOM mixes with just UTF8 it makes more work for everyone like crappy PRs. Because of people for who those are things that „don’t matter in grand scheme of things”.
Hey not every rebase has conflicts. I definitely rebase when there are no conflicts, then merge.
When there are conflicts I merge „theirs” into my branch to resolve those so I keep mental model for this side and don’t have to switch. Then rebase then open PR.
I do the following to keep my sanity when doing something like rebasing a feature branch onto latest origin/master:
* First and most important: turn on rerere.
* Second: merge and resolve all conflicts, commit.
* Third: rebase.
The second step might look redundant, but thanks to rerere git remembers the merge conflict resolution. That makes step 3 have fewer conflicts; and step 2 tends to be easier on me, because we are only reconciling the final outcomes.
(Well, I'm lying: the above is what I used to do. Nowadays I let Claude handle that, and only intervene when it gets too complicated for the bot.)
This is one of my pain points, and one time I googled and got the real answer (which is why it's such a pain point).
That answer is "It depends on the context"
> The reason the "ours" and "theirs" notions get swapped around during rebase is that rebase works by doing a series of cherry-picks, into an anonymous branch (detached HEAD mode). The target branch is the anonymous branch, and the merge-from branch is your original (pre-rebase) branch: so "--ours" means the anonymous one rebase is building while "--theirs" means "our branch being rebased".[0]
I ended up creating a personal vim plugin for merges one night because of a frustrating merge experience and never being able to remember what is what. It presents just two diff panes at top to reduce the cognitive load and a navigation list in a third split below to switch between diffs or final buffer (local/remote, base/local, base/remote and final). The list has branch names next to local/remote so you always know what is what. And most of the time the local/remote diff is what I am interested in so that’s what it shows first.
Let’s see if I get this wrong after 25 years of git:
ours means what is in my local codebase.
theirs means what is being merged into my local codebase.
I find it best to avoid merge conflicts than to try to resolve them. Strategies that keep branches short lived and frequently merging main into them helps a lot.
"Ours" and "theirs" make sense in most cases (since "ours" refers to the HEAD you're merging into).
Rebases are the sole exception (in typical use) because ours/theirs is reversed, since you're merging HEAD into the other branch. Personally, I prefer merge commits over rebases if possible; they make PRs harder for others to review by breaking the "see changes since last review" feature. Git generally works better without rebases and squash commits.
Wow, interesting to see such a diametrically opposed view. We’ve banned merge commits internally and our entire workflow is rebase driven. Generally, I find that rebases are far better at keeping Git history clean and clearly allowing you to see the diff between the base you’re merging into and the changes you’ve made.
"Clean" is not the same as "useful". You have to be really, really disciplined to not make a superficially looking "clean" history which may appear linear but which is actually total nonsense.
For example, if one is frequently doing "fix after rebase" commits, then they are doing it wrong and are making a history which is much less useful than a seemingly more complicated merge based history. Rebased histories are only clean if they also tell a true story after the rebase, but if you push "rebase fixes" onto the end of your history, then it means that prior rebased commits no longer make any sense because they e.g. use APIs that aren't actually there. Giving up and squashing everything to one commit is almost better in this case because it at least won't throw off someone who is trying to make sense of the history in the future.
I think that rebasing has won over merges mostly because the tools for navigating git histories suck SO HARD. I have used Perforce at a previous job, and their graphical tools for navigating a merge based history are excellent and were really useful for doing code archeology.
Generally our pattern is that every PR gets rebased into sensible commits. So in a way we are doing "squash commits" but the method is an interactive rebase. This keeps our history very pretty and clean, and simultaneously easy to grok and navigate.
Yes, I prefer that approach as well because it allows the person who authored the change to do all the work of deciding how to resolve conflicts up front (and allows reviewers to review that conflict resolution) instead of forcing whoever eventually does the merge to figure everything out after the fact. It also removes conflicts from the history so you never have to think about them later after the rebase/merge process is finished.
I don't know. Even when I'm working on my own private repositories across several machines, I really, really dislike regular merges. You get an ugly commit message and I can never get git log to show me the information I actually want to see.
For me, rebasing is the simplest and easiest to understand, and it allows you to squash some of your commits so that it's one commit per feature / bug-fix / logical unit of work. I'll also frequently rebase and squash commits in my work branch too, where I've temporarily committed something and then fixed a bug before it's been pushed into main, I'll just reorder and squash the relevant commits into one.
I completely agree, since doing rebase our history looks fantastic and it makes finding things, cherrypicking and generating changelogs really simple. Why not be neat, it's cost us nothing and you can make yourself a tutorial on Claude if you don't understand rebasing pretty easily.
The thing is, you'll typically switch to master to merge your own branch. This makes your own branch 'theirs', which is where the confusion comes from.
Not me. I typically merge main onto a feature branch where all the conflicts are resolved in a sane way. Then I checkout main and merge the feature branch into it with no conflicts.
As a bonus I can then also merge the feature branch into main as a squash commit, ditching the history of a feature branch for one large commit that implements the feature. There is no point in having half implemented and/or buggy commits from the feature branch clogging up my main history. Nobody should ever need to revert main to that state and if I really really need to look at that particular code commit I can still find it in the feature branch history.
This is what I do, and I was taught by an experienced Git user over a decade ago. I've been doing it ever since. All my merges into main are fast forwards.
Since it's always one person doing a merge, why isn't it "mine" instead of "ours"? There aren't five of us at my computer collaboratively merging in a PR. There is one person doing it.
"Ours" makes it sound like some branch everyone who's working on the repo already has access to, not the active branch on my machine.
I always checkout the branch I am merging something into. I was vaguely aware I could have main checked out but merge foo into bar but have never once done that.
I have met more than one person who would doggedly tolerate rebase, not even using rerere, instead of doing a simple ‘git merge --no-ff’ to one-shot it, not understanding that rebase touches every commit in the diff between main and not simply the latest change on HEAD.
Not a problem if you are a purist on linear history.
I was wondering when someone was going to point it out. I actually have only been using it since about 2009 after a brief flirtation with SVN and a horrible breakup with CVS.
I was thinking about creating a TUI application that points out what each part in the conflict indicator corresponds to. This idea is primarily meant for rebases where the HEAD and the ID of the updated commits change constantly. Think of it as a map view of the rebase process, that improves your situational awareness by presenting all the relevant information simultaneously. That could trivially work for merges too.
iirc ours is always the commit the merge is starting from. the issue is that with a merge your current commit is the merging commit while with a rebase it is reversed.
I suspect that this could be because the rebase command is implemented as a serie of merges/cherry-picks from the target branch.
Now git takes main and starts cloning (cherry-picking, as you said) commits from mybranch on top of it. From git's viewpoint it's working on top of main, so if a conflict occurs, main is "ours" and mybranch is "theirs". But from your viewpoint you're still on mybranch, and indeed are left on mybranch when the rebase is complete. (It's a different mybranch, of course; once the rebase is completed, git moves mybranch to point to the new (detached) HEAD.) Which makes "ours" and "theirs" exactly the opposite of what the user expects.
It will checkout origin/master and replay the current branch on top.
P.S. I had to check the man page as I use Magit. In the latter I tap r, then u. In magit my upstream is usually the main trunk. You can also tap e instead of u to choose the base branch.
>Maybe "local/alien" might be a less pompous vocabulary to convey the same idea.
That is more alien and just as contrived. If you merge branches that you made, they're both local and "ours". You just have to remember that "ours" is the branch you are on, and "theirs" is the other one. I have no idea what happens in an octopus merge but anyway, the option exists to show commit titles along with markers to help you keep it straight.
Something that carry the meaning "the branch we want to use as a starting point" and "the other branch we want to integrate in the previous one" is what I had in mind, but it might not fit all situations in git merge/rebase.
Assuming you have to start on one of the branches being merged, "current" is a good name for the one you started on. "Other" is good enough for the other one. By the way I found out that octopus merges never succeed in case of conflicts. I'm not even sure if prerecorded resolutions work in that case. You're supposed to do a series of normal merges instead if you have conflicts.
This is better but it still doesn't really help when the conflict is 1000 lines and one side changed one character and the other deleted the whole thing. That isn't theoretical - it happens quite regularly.
What you really need is the ability to diff the base and "ours" or "theirs". I've found most different UIs can't do this. VSCode can, but it's difficult to get to.
I haven't tried p4merge though - if it can do that I'm sold!
If I understood your point correctly, I believe that Meld can do that. And then you get a windows as [1]. You can configure git to choose which version goes where. Something like:
So the way you can do it in VSCode is to open the conflict in their smart merge editor... Often it is actually smart enough to highlight the relevant change but if not each of the left/right editors has a button in its toolbar to diff it against the base.
Not the easiest to access but better than copying/pasting (which is what I also used to do).
I'm on my phone right now so I'm not going to dig too hard for this, but you can also configure a "merge tool" (or something like that) so you can use Meld or Kompare to make the process easier. This has helped me in a pinch to work out some confusing merge conflicts.
I've trained myself to avoid this entirely by avoiding changing lines unnecessarily. With LLMs, I also force them to stay concise and ONLY change what is absolutely necessary.
> I don't understand why you need to switch out the VCS to fix that issue.
For some reason, when it comes to this subject, most people don't think about the problem as much as they think they've thought about it.
I recently listened to an episode on a well-liked and respected podcast featuring a guest there to talk about version control systems—including their own new one they were there to promote—and what factors make their industry different from other subfields of software development, and why a new approach to version control was needed. They came across as thoughtful but exasperated with the status quo and brought up issues worthy of consideration while mostly sticking to high-level claims. But after something like a half hour or 45 minutes into the episode, as they were preparing to descend from the high level and get into the nitty gritty of their new VCS, they made an offhand comment contrasting its abilities with Git's, referencing Git's approach/design wrt how it "stores diffs" between revisions of a file. I was bowled over.
For someone to be in that position and not have done even a cursory amount of research before embarking on a months (years) long project to design, implement, and then go on the talk circuit to present their VCS really highlighted that the familiar strain of NIH is still alive, even in the current era where it's become a norm for people to be downright resistant to writing a couple dozen lines of code themselves if there is no existing package to import from NPM/Cargo/PyPI/whatever that purports to solve the problem.
> they made an offhand comment contrasting its abilities with Git's, referencing Git's approach/design wrt how it "stores diffs" between revisions of a file. I was bowled over.
It seems like you have taken offense to the phrase "stores diffs", but I'm not sure why. I understand how commit snapshots and packfiles work, and the way delta compression works in packfiles might lead me to calling it "storing diffs" in a colloquial setting.
> It seems like you have taken offense to the phrase "stores diffs", but I'm not sure why.
Yeah, I'm not sure why it seems that way to you, either.
> the way delta compression works in packfiles might lead me to calling it "storing diffs" in a colloquial setting
We're not discussing some fragment of some historical artifact, one part of a larger manuscript that has been lost or destroyed, with us left at best trying to guess what they meant based on the little that we do have, which amounts to nothing more than the words that you're focusing on here.
Their remarks were situated within a context, and they went on to speak for another hour and a half about the topic. The fullness of that context—which was the basis of my decision to comment—involved that person's very real and very evident overriding familiarity with non-DVCS systems that predate Git and that familiarity being treated as a substitute for being knowledgeable about how Git itself works when discussing it in a conversation about the tradeoffs that different version control systems force you to make.
A common misconception is that git works with diffs as a primary representation of patches, and that's the implied reading of "stores diffs". Yes, git uses diffs as an optimisation for storage but the underlying model is always that of storing whole trees (DAGs of trees, even), so someone talking about it storing diffs is missing something fundamental. Even renames are rederived regularly and not stored as such.
However, context would matter and wasn't provided - without it, we're just guessing.
Seconding the use of p4merge for easy-to-use three-pane merging. Just like most other issues with Git, if your merges are painful it's probably due to terrible native UX design - not due to anything conceptually wrong with Git.
Did you know that VS Code added support for the same four-pane view as p4merge years ago? I used p4merge as my merge tool for a long time, but I switched to VS Code when I discovered that, as VS Code’s syntax highlighting and text editing features are much better than p4merge’s.
I also use the merge tool of JetBrains IDEs such as IntelliJ IDEA (https://www.jetbrains.com/help/idea/resolve-conflicts.html#r...) when working in those IDEs. It uses a three-pane view, not a four-pane view, but there is a menu that allows you to easily open a comparison between any two of the four versions of the file in a new window, so I find it similarly efficient.
Thirding it except I do it from Emacs. Three side-by-side pane with left / common ancestor / right and then below the merge result. By default it's not like that but then it's Emacs so anything is doable. I hacked some elisp code a great many years ago and I've been using it ever since.
No matter the tool, merges should always be presented like that. It's the only presentation that makes sense.
The extensibility provided with Emacs Lisp has been helpful for hacking together my own Git/Jujutsu plugin. I tried to model it over lazygit/lazyjj although magit has been incredible to use and hard to depart from.
I think you need to enable 3 way merge by default in git's configuration, and both smerge (minor mode for solving conflicts) and ediff (major mode that encompass diff and patch) will pick it up. In the case of the latter you will have 4 panes, one for version A, another for version B, a third for the result C, and the last is the common ancestor of A and B.
Addendum:
I've since long disabled it. A and B changes are enough for me, especially as I rebase instead of merging.
I often find myself using the gitlens in vscode, to do something similar. I'd compare the working tree to the common base. Then I have the left pane with what's already in the base, the right pane is editable with the result in it.
It's nice to have all the LSP features available too while editing.
There isn't. Git plumbing is elastic enough that you could have way different workflows built on top of it and still have repo that is usable by other tools.
Hell, git tools themselves offer a ton of customization, you can have both display and diff command different than the builtin very easily.
Some of Git defaults and command syntax might suck but all of that can be fixed without touching repo format
If I proposed putting mandatory cameras in all homes and you objected, would it then be fair for me to demand that you justify your position by proposing a better alternative to combat domestic violence?
Locking down computing is just fundamentally wrong and leads to an unfree society.
A corollary of this statement is that code without a spec is not code. No /s, I think that is true - code without a spec certainly does something, but it is, by the absence of a detailed spec, undefined behavior.
Code is a specific implementation of a spec. You can even use it as a spec if you're happy to accept exactly what the code does. But the code doesn't tell you what was supposed to be built so the code is not a spec.
Simple thought experiment: Imagine you have a spec and some code that implements it. You check it, and find that a requirement in the spec was missed. Obviously that code is not the spec; the spec is the spec. But also you couldn't even use the code as a spec because it was wrong. Now remove the spec.
Is the code a spec for what was supposed to be built? No. A requirement was missed. Can you tell from just the code? Also no. You need a two separate sources that tell you what was meant to be written in case the either of them is wrong. That is usually a spec and the code.
They could both be wrong, and often are, but that's a people problem.
> Obviously that code is not the spec; the spec is the spec. But also you couldn't even use the code as a spec because it was wrong.
Or the spec was wrong and the code was right; that happens more often than you might think. If we view it through the lens of "you have two specs, one of which is executable" then obviously you could have made an error in either spec, and obviously writing two specs and checking for mismatches between them is one possible way to increase the fidelity of what you wrote, but it's nothing more than that.
That assumes that the two have equal 'authority' though. Really one of the two should be the source of truth, and that's usually the spec. That's definitely the one that the should win if there's a difference in my experience.
No way! Code is whatever defines the behavior of the program unambiguously, or as close to unambiguously as makes little difference. A sufficiently detailed spec does that, and hence it is effectively higher level code. Code (together with the language spec and/or compiler) always does that, regardless of how haphazardly written it is.
Wouldn't a much simpler approach be to have everyone log in to a common server which sits on a VPN with all the VMs? It introduces an extra hop, but this is a pretty minor inconvenience and can be scripted away.
They kind of already have a central point with 'ssh exe.dev', which hosts the interface for provisioning new VMs. But yeah, still one extra step for the user.
I also wonder what happens if you want to grant access to your VM to additional public keys and one of those public keys happen to already be routed to a different VM on the same IP.
The server matches your purposed public key with one in the authorized keys file. If you don't want to expose your raw public key to the server, you'll need to generate and send the hashed key format into the authorized keys file, which at that point is the same as just generating a new purpose built key, no? Am I missing something?
{kind=link}
If you are a serious software developer, then you will probably be able to explain both what your code does (i.e. what spec it implements) and how it does it (what does it call, what algorithms does it use, what properties does it rely on?). With the advent of LLMs, people have started to accept not having a clue about the "how", and I fear that we are also starting to sacrifice the "what". Unless our LLMs get context windows that are large enough to hold the source of the full software stack, including LLM-generated dependencies, then I think that sacrificing the "what" is going to lead to disaster. APIs will be designed and modified with only the use cases that fit in the modifying agents context window in mind with little regard for downstream consequences and stability of behavior, because there is not even a definition of what the behavior is supposed to be.
reply